
Siga o Olhar Digital no Google Discover
Depois de quase 16 horas de instabilidades, a Amazon Web Services (AWS), divisão de computação em nuvem da Amazon, confirmou que todos os seus serviços voltaram a operar normalmente na noite desta segunda-feira (20).
Ofertas

Por: R$ 37,92

Por: R$ 22,59

Por: R$ 59,95

Por: R$ 3.099,00

Por: R$ 3.324,00

Por: R$ 799,00

Por: R$ 241,44
Por: R$ 349,90

Por: R$ 2.159,00

Por: R$ 188,99

Por: R$ 45,00

Por: R$ 379,00

Por: R$ 1.239,90

Por: R$ 943,20

Por: R$ 798,99

Por: R$ 205,91

Por: R$ 476,10

Por: R$ 1.139,05

Por: R$ 949,00

Por: R$ 7,60

Por: R$ 21,77

Por: R$ 16,63

Por: R$ 59,95


Por: R$ 7,20

Por: R$ 139,90

Por: R$ 119,90

Por: R$ 398,99

Por: R$ 79,90

Por: R$ 199,90
A falha global provocou interrupções em centenas de plataformas e aplicativos populares, incluindo Alexa, Zoom, Duolingo, Snapchat, Fortnite, Mercado Livre e Prime Video.
O problema começou a ser identificado por volta das 4h11 (horário de Brasília) e atingiu pelo menos mil empresas, segundo dados compilados pelo site Downdetector. No pico do incidente, mais de 6,5 milhões de usuários em diferentes países relataram falhas de acesso.
Embora a situação tenha começado a se normalizar nas primeiras horas da manhã, a Amazon informou que a recuperação completa da região US-EAST-1 (norte da Virgínia, EUA) foi concluída apenas por volta das 19h53, quando todos os serviços voltaram ao funcionamento normal.

O que causou a falha na AWS?
O problema se concentrou na região US-EAST-1, no norte da Virgínia (EUA), onde fica um dos principais data centers da Amazon Web Services. Essa área é estratégica, pois abriga parte essencial da infraestrutura que sustenta operações globais da empresa.
De acordo com a AWS, a falha começou com problemas de resolução de DNS no serviço DynamoDB, que afetaram também recursos interligados como IAM e DynamoDB Global Tables. A interrupção se espalhou rapidamente, gerando lentidão e erros de conexão em outros serviços hospedados na mesma região.
Após corrigir o erro de DNS, nas primeiras horas da manhã, a empresa identificou uma nova falha em um subsistema interno do EC2, responsável por lançar novas instâncias virtuais. Esse subsistema dependia do DynamoDB, que ainda se recuperava, o que acabou provocando erros em cascata.
A instabilidade atingiu também os balanceadores de carga de rede (Network Load Balancers) – responsáveis por monitorar o tráfego interno – e causou problemas de conectividade em serviços como Lambda, CloudWatch e o próprio DynamoDB.
Para conter o impacto, a AWS aplicou medidas de mitigação, como a limitação temporária de novas instâncias EC2, ajustes na execução de funções Lambda e a redução no processamento de filas SQS, até que os sistemas se estabilizassem.
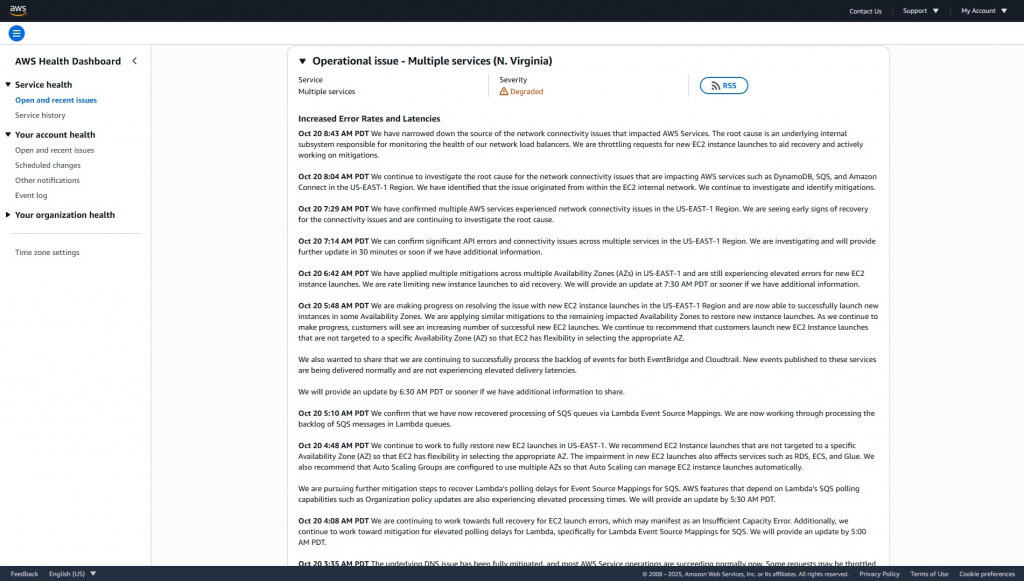
Ao longo do dia, a empresa relatou recuperação gradual: as zonas de disponibilidade começaram a se restabelecer, com aumento nos lançamentos bem-sucedidos de EC2 e redução dos erros de rede. As funções Lambda voltaram a operar normalmente e o backlog de filas SQS passou a ser processado sem atrasos.
Por volta das 18h48, a AWS informou que os lançamentos de novas instâncias EC2 foram totalmente normalizados em todas as zonas da região afetada. Serviços dependentes, como Redshift, já processavam o backlog acumulado, e o Amazon Connect voltou a operar normalmente.
Segundo a empresa, todos os serviços da AWS retornaram ao funcionamento normal às 19h53, e sistemas como AWS Config, Redshift e Connect ainda processavam mensagens pendentes; porém, sem impacto para os usuários.
Falha gravíssima afeta confiabilidade da nuvem
Segundo Arthur Igreja, especialista em tecnologia e inovação, a falha foi gravíssima e afetou diretamente a confiabilidade da nuvem. Ele explica que o problema envolveu uma falha de DNS, que funciona como a “lista telefônica da internet”. Quando o DNS fica indisponível, os aplicativos não conseguem acessar suas bases de dados, tornando serviços inoperantes por algumas horas.
É uma falha técnica gravíssima porque um dos requisitos da nuvem é justamente confiabilidade e disponibilidade. Muitas empresas ficam expostas, sem plano B, sem alternativa quando algo assim acontece.
Arthur Igreja, especialista em tecnologia e inovação
O especialista reforça que, mesmo após a Amazon reestabelecer os serviços, a recuperação completa leva horas, já que são aplicações complexas e de grande escala, não bastando um simples reboot para resolver o problema.
Serviços e aplicativos impactados pelo apagão da AWS
Além de interromper o funcionamento de aplicativos amplamente usados, como Zoom, Alexa, Duolingo, Snapchat, Prime Video, Fortnite, Roblox, Coinbase, Mercado Livre e Mercado Pago, a falha também afetou operações de companhias aéreas e outros bancos e plataformas de e-commerce. Estimativas indicam que mais de mil empresas foram atingidas em diferentes setores.
No Brasil, o incidente afetou principalmente fintechs e plataformas de e-commerce, enquanto a maior parte dos aplicativos atingidos pertence ao mercado americano. Segundo relatórios de usuários e monitoramento de instabilidades, mais de 500 aplicativos enfrentaram interrupções temporárias, refletindo a dependência crescente de empresas e usuários de uma infraestrutura de nuvem centralizada.
O caso reacende o debate sobre a dependência de serviços de nuvem concentrados em poucas big techs. Especialistas apontam que, com cerca de um terço da internet apoiada na AWS, falhas em um único datacenter podem gerar um efeito dominó sobre sistemas digitais no mundo todo.
A Amazon informou que seus engenheiros seguem monitorando o desempenho da rede e que a maioria dos serviços já foi restaurada. Até as 19h53, 142 produtos afetados apareciam como “resolvidos” na página de integridade da AWS.

Linha do tempo das falhas da AWS nesta segunda (20)
A empresa publicou uma série de atualizações detalhando os problemas, suas causas e as medidas de mitigação adotadas ao longo do dia. A seguir, confira a cronologia dos acontecimentos conforme relatado pela própria AWS.
- 4h11: A AWS iniciou a investigação após identificar aumento de erros e latências em diversos serviços na região US-EAST-1.
- 4h51: A empresa confirmou o aumento de falhas e alertou que a criação de casos no AWS Support também poderia ser afetada. Engenheiros começaram medidas de mitigação enquanto buscavam a causa do problema.
- 5h26: Erros significativos foram registrados no endpoint do DynamoDB, afetando também outros serviços. Clientes relatavam dificuldade para criar ou atualizar casos no suporte.
- 6h01: A AWS apontou a resolução de DNS do endpoint do DynamoDB como possível causa raiz. A falha também impactava serviços globais dependentes da região US-EAST-1.
- 6h22: A empresa aplicou medidas iniciais de mitigação e informou sinais de recuperação em alguns serviços, embora falhas ainda pudessem ocorrer e backlog de operações permanecesse.
- 6h27: A maioria das solicitações começou a ser processada normalmente, mas o trabalho para reduzir o backlog continuava.
- 7h03: Serviços afetados apresentaram recuperação significativa, incluindo aqueles globais que dependem de US-EAST-1.
- 7h35: Problema de DNS totalmente resolvido, mas solicitações de novas instâncias EC2 ainda apresentavam erros elevados. Serviços como CloudTrail e Lambda continuavam processando backlog de eventos.
- 8h08: A AWS seguia trabalhando para restaurar lançamentos de EC2 e reduzir atrasos no polling de Lambda para filas SQS.
- 8h48: Empresa recomendou lançar instâncias EC2 sem especificar a Availability Zone para acelerar a recuperação. Serviços dependentes, como RDS, ECS e Glue, também eram afetados.
- 9h10: Processamento de filas SQS via Lambda voltou a ocorrer normalmente, com backlog sendo gradualmente resolvido.
- 9h48: Recuperação parcial de EC2 em algumas zonas; mitigação sendo aplicada nas demais. EventBridge e CloudTrail operavam sem atrasos significativos.
- 10h42: Múltiplas medidas foram aplicadas em todas as Availability Zones de US-EAST-1, mas lançamentos de EC2 ainda registravam erros. Rate limiting foi implementado para auxiliar na recuperação.
- 11h14: AWS confirmou que diversos serviços continuavam com erros e problemas de conectividade; investigação da causa prosseguia.
- 11h29: A empresa observou os primeiros sinais de recuperação da conectividade com os serviços afetados.
- 12h04: Problema identificado na rede interna do EC2, afetando serviços como DynamoDB, SQS e Amazon Connect. Mitigações começaram a ser aplicadas.
- 12h43: AWS apontou que a origem do problema estava em um subsistema interno de monitoramento dos network load balancers. Lançamentos de EC2 foram temporariamente limitados para auxiliar na recuperação.
- 13h13: Mitigações adicionais trouxeram recuperação gradual da conectividade e das APIs; limitações em novos lançamentos de EC2 ainda eram gerenciadas.
- 14h03: AWS informou que continuava aplicando medidas de mitigação. Erros em funções Lambda persistiam devido ao subsistema afetado, e a correção para lançamentos de EC2 estava sendo validada.
- 14h38: A AWS informou que as medidas de mitigação para falhas no lançamento de novas instâncias EC2 avançavam e que alguns subsistemas internos do EC2 já apresentavam sinais iniciais de recuperação em algumas Availability Zones na região US-EAST-1. A empresa aplicava mitigação nas demais AZs, com expectativa de que erros de lançamento e problemas de conectividade de rede diminuíssem.
- 15h22: A AWS relatou avanços contínuos nas medidas para corrigir falhas no lançamento de novas instâncias EC2, observando aumento nas implantações bem-sucedidas e redução dos problemas de conectividade na região US-EAST-1. A empresa também destacou melhora significativa nos erros de invocação do Lambda, especialmente durante a criação de novos ambientes de execução, incluindo o Lambda@Edge.
- 16h15: A AWS informou avanço na recuperação dos serviços e sucesso no lançamento de instâncias EC2 em várias zonas da região US-EAST-1. Funções Lambda ainda podiam apresentar erros ocasionais, mas a empresa começou a aumentar novamente a taxa de polling de filas SQS conforme o serviço se estabilizava.
- 17h03: A empresa relatou melhora geral na recuperação dos serviços, com redução das restrições a novos lançamentos de EC2. Os erros de invocação do Lambda foram totalmente resolvidos e o polling de SQS voltou ao nível normal.
- 18h48: A AWS informou que os lançamentos de instâncias EC2 foram totalmente normalizados em todas as zonas da região US-EAST-1. Serviços dependentes, como Redshift, já processavam o backlog acumulado. O Amazon Connect voltou a operar normalmente.
- 19h53: A Amazon informou que todos os serviços da AWS voltaram a operar normalmente após quase 15 horas de instabilidades na região US-EAST-1, no norte da Virgínia (EUA). O problema, iniciado por uma falha de DNS no DynamoDB, desencadeou erros em cascata que afetaram EC2, Lambda, CloudWatch e dezenas de outros serviços. Segundo a empresa, alguns sistemas (como Redshift, AWS Config e Connect) ainda processam o backlog de mensagens, mas sem impacto para os clientes.
Leia mais:
- Veja quais foram os celulares mais vendidos na Amazon em setembro de 2025
- Como encontrar eletrônicos novos ou usados na Amazon Quase Novo e pagar mais barato
- Amazon: como gerenciar a biblioteca de aplicativos
Um lembrete sobre a fragilidade da internet
Embora a falha tenha sido controlada em poucas horas, o episódio mostra como a infraestrutura da internet continua vulnerável a interrupções em larga escala. Casos semelhantes já haviam ocorrido em anos anteriores, como o colapso nos sistemas da CrowdStrike em 2024, que paralisou aeroportos, bancos e hospitais em diferentes países.
Com o crescimento da demanda por armazenamento e inteligência artificial, o desafio de garantir resiliência e redundância em grandes provedores de nuvem tende a aumentar. E, enquanto poucas empresas concentram boa parte da infraestrutura digital global, qualquer instabilidade pode rapidamente se transformar em um apagão mundial.
Assista a filmes e séries
Assine Amazon Prime para assistir a filmes e séries populares, incluindo Amazon Originals premiados. O Amazon Prime também inclui a entrega GRÁTIS e rápida de milhares de itens elegíveis, mais de 2 milhões de músicas sem anúncios e muito mais. Clique aqui e comece seu teste GRÁTIS por 30 dias!

